
In Michael Taylor’s work as a prompt engineer, he’s found that many of the issues he encounters in managing AI tools—such as their inconsistency, tendency to make things up, and lack of creativity—are ones he used to struggle with when he ran a marketing agency. It’s all about giving these tools the right context to do the job, just like with humans. In the latest piece in his series Also True for Humans, about managing LLMs like you'd manage people, Michael explores self-consistency sampling, where you generate multiple responses from the LLM to arrive at the right answer. Every company with more than one person with the same job title does this to some extent—so start hiring more than one AI worker at a time. Plus: Learn how to best position yourself to compete against AI coworkers in the future.—Kate Lee
In my former life as the founder of a 50-person marketing agency that spent over $10 million on Facebook ads per year, I employed one trick to ensure that I always delivered for clients: I hired multiple people to do the same task. If I needed fresh creative designs and copy for Facebook advertising campaigns, I’d give three different designers the same brief. My thinking was that it was better to pay $200 each to three designers than risk losing a $20,000-a-month client. The chances were high that at least one of the three would deliver something the client liked.Creative work is unpredictable by nature, and even great designers have off days or miss deadlines. I was comfortable with the trade-off: higher cost for greater reliability.
Now AI is doing some of that work, making it easier than ever to apply the principle of repetition. While your colleagues might be upset to learn you had given the same task to multiple people (“Don’t you trust me!?”), your AI coworkers don’t know, and don’t care. It’s trivial work to generate three or more responses with the same prompt and compare them to see which one you like best. This technique is called “self-consistency sampling,” and you can use it to make the trade-off between cost and reliability with AI.
Generative AI models are non-deterministic—they give you a different answer every time—but if you run the same prompt multiple times, you can take the most common answer as the final answer. I do this all the time in my professional work as a prompt engineer building AI applications, and as a user of AI tools. The simplest implementation of this concept is to hit the “Try again” button multiple times in ChatGPT to see how often I get the same answer. My co-author James Phoenix does the same thing by programming scripts that call ChatGPT’s API hundreds of times, counting the most common answer to major decisions. By urging the model to “Try again”—five or 500 times—you can get a better sense of the range of potential answers.
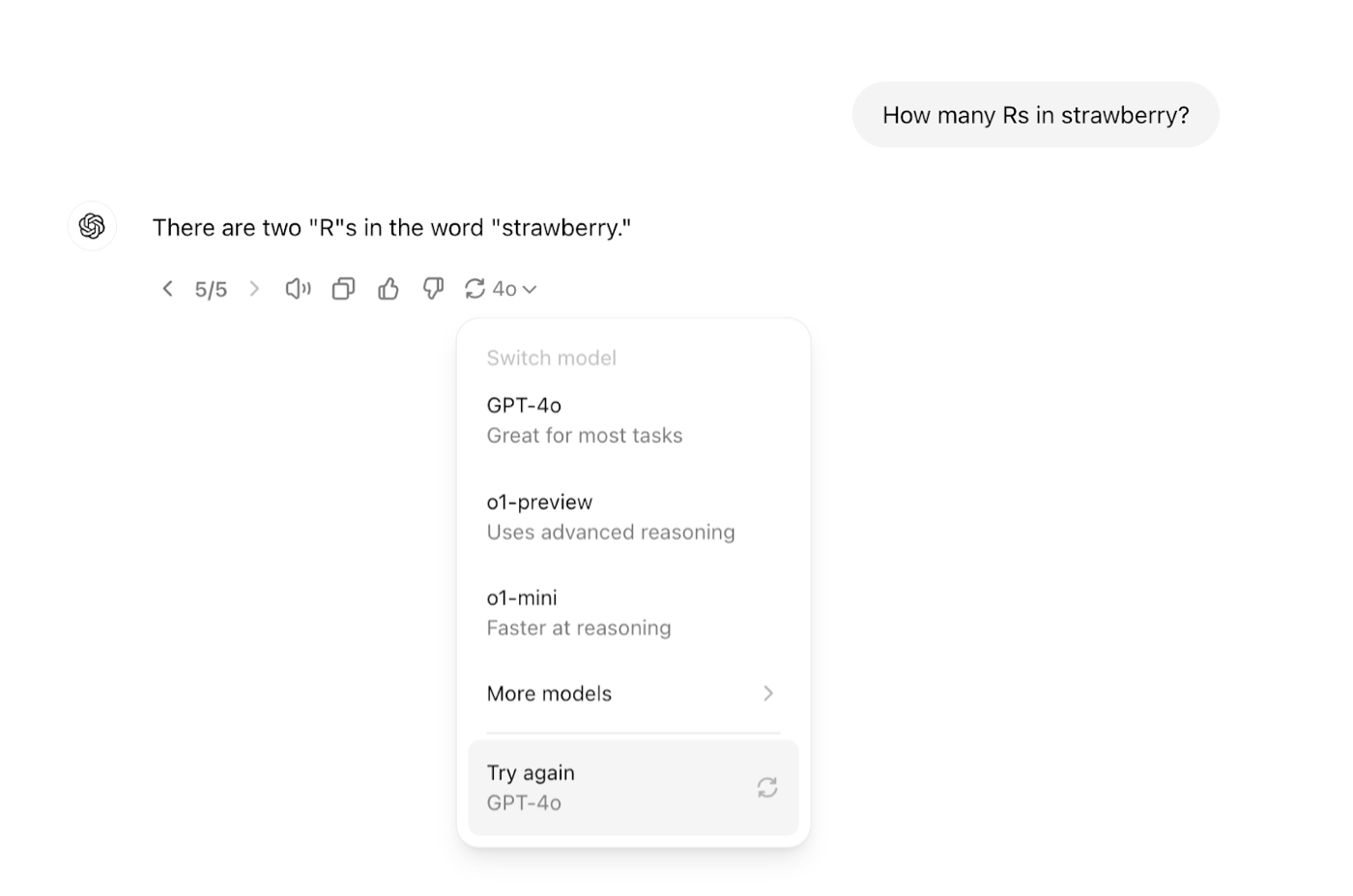
The realization that you can throw more AI at a problem and increase your chances of success is deceptively powerful, even if any one attempt is likely to be wrong. Let’s walk through how to take advantage of this technique—as well as the implications for your own work.
Become a paid subscriber to Every to unlock this piece and learn how:
- AI's willingness to repeat tasks
- How self-consistency sampling improves results
- Rethinking career strategies in the age of AI
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools




 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software

 Mike Taylor
Mike Taylor

