
With new and improved LLMs coming out almost constantly, it’s tempting to always reach for the latest iteration, the one that promises unprecedented performance—with a commensurate price tag. But in exhaustive testing of 12 leading AI models, Michael Taylor found a counterintuitive truth: When it comes to mimicking human behavior, you can't buy authenticity. For anyone building products, testing ideas, or conducting audience-based research with AI, this data-driven exploration will help you pick the model that will get more done while keeping costs down.—Kate Lee
Was this newsletter forwarded to you? Sign up to get it in your inbox.
After running 60 experiments testing how well AI models can roleplay as real people, I discovered you can’t buy your way to quality. The model that sounds most believably human costs just $0.008 per 100 responses, while the most expensive option delivers robotic, overthought answers at 23 times the price.
At Ask Rally, we build audience simulators that use AI personas to model likely human behavior. As an alternative to traditional focus groups and surveys, you could get 80 percent of the insights at 1 percent of the cost. For early-stage work––from drafting a social media post to planning a product launch––it helps you gauge whether your ideas will resonate with a target audience before committing significant time or budget.
However, AI personas are only useful to the extent that the responses they give match up with what people would say if you ran a real-world study.
So I took five market research studies that had been done using groups of people and ran them using AI personas, then compared the results. I ran the same test across 12 leading models. The goal was simple—find out which LLM actually understands humans best, at an affordable price.
There were several surprises.

Make your team AI‑native
Scattered tools slow teams down. Every Teams gives your whole organization full access to Every and our AI apps—Sparkle to organize files, Spiral to write well, Cora to manage email, and Monologue for smart dictation—plus our daily newsletter, subscriber‑only livestreams, Discord, and course discounts. One subscription to keep your company at the AI frontier. Trusted by 200+ AI-native companies—including The Browser Company, Portola, and Stainless.
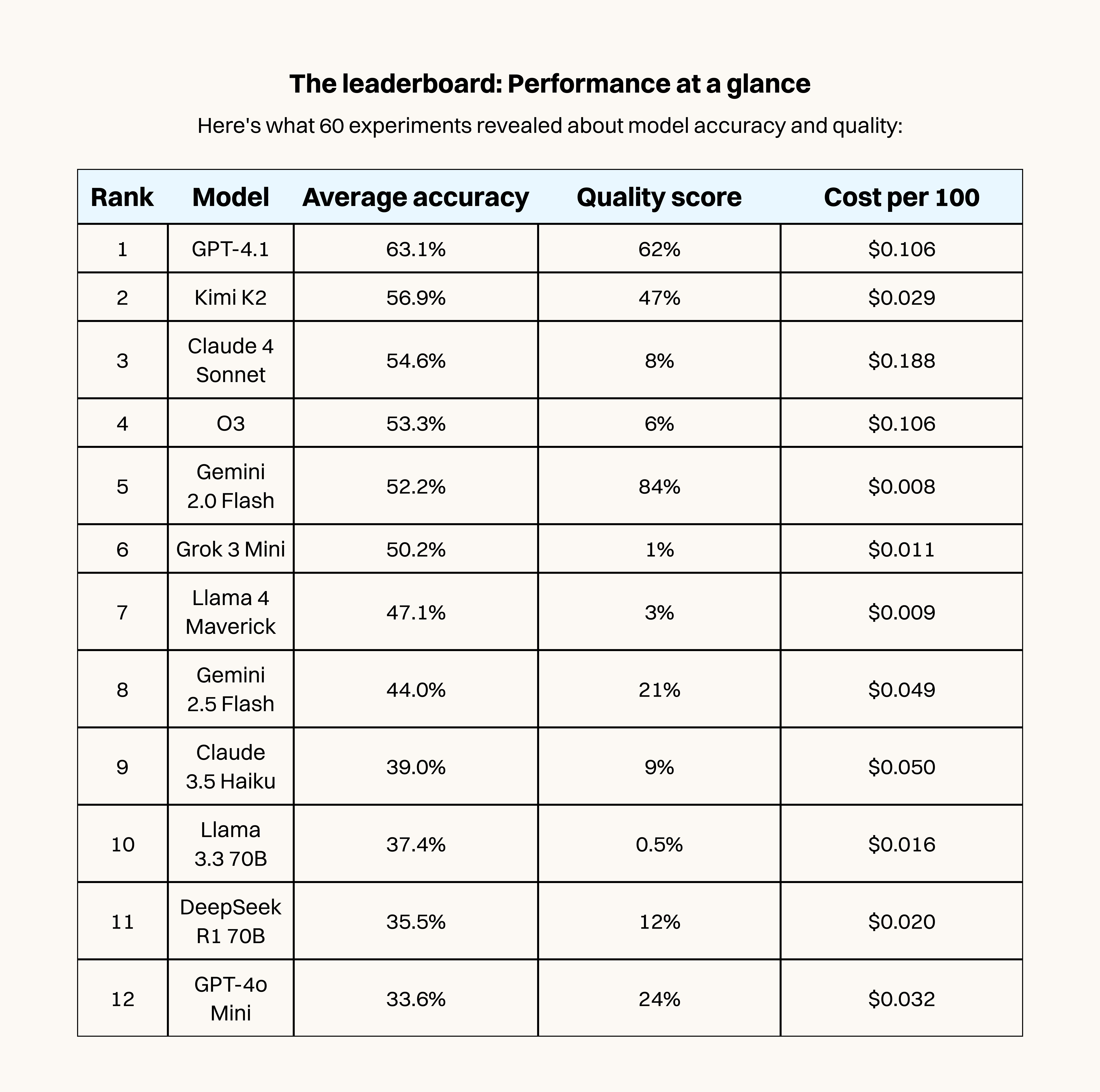
High accuracy does not equal quality
The first thing I learned was that there’s a difference between being accurate—making the same choices as humans did in real-world studies—and sounding human. Accuracy is probably going to be your biggest consideration in most cases. But I also wanted to capture how models were giving their answers, because AI personas have to sound like real humans to be believable. To do that, I used another LLM I had previously trained on a database of AI and human responses to recognize the difference. Then I told the LLM to read the AI personas’ outputs and tell me how human they sounded. I call this metric “quality.”
To give this some grounding, let’s look at one study in our test, in which we tried to replicate gamers’ preferences for various kinds of new products. We created an AI audience with the same characteristics as the human audience who participated in the study: U.S.-based mobile games players ages 25 to 54 (mostly 35-44), a 66:33 male-to-female ratio, interested in a wide selection of game categories. Given the same questions as appeared in the study, did the AI personas vote for the same answers as their human counterparts, and did their answers sound believably human? Here’s what one persona’s response looked like in two of the models we tested.

We ran the gamer preferences study and four others from a variety of domains, including politics, purchasing decisions, and B2B lead generation, using the same accuracy and quality metrics tested across each model.
In our study, Gemini 2.0 Flash achieved an 84 percent quality score despite 52.2 percent voting accuracy, but was incredibly cheap at just $0.08 per hundred responses. Meanwhile, Claude 4 Sonnet cost 23 times more ($0.188 per hundred) and did better on accuracy (54.6 percent), but scored just 8 percent on quality.
Individual studies reached 70-80 percent accuracy (we even saw accuracy scores above 80 percent in some cases), but our most challenging study—a replication of a Facebook Ads A/B test, which tested different headlines targeted at parents of college applicants—achieved a 10.1 percent average and significantly lowered overall scores (see endnote on methodology).
The surprise winners
GPT-4.1: Better than expected
I'll admit, when GPT-4.1 came out I thought it was a step backwards. Maybe I was accustomed to dealing with GPT-4o, but based on vibes alone I dismissed the model too soon. When we measured actual predictive accuracy against real human behavior, GPT-4.1 consistently outperformed its predecessor. The numbers don't lie—it achieved the highest accuracy, at 63.1 percent, while maintaining good quality scores around 62 percent. Sometimes simpler is better, and the price is very competitive for an OpenAI-hosted model.
Gemini 2.0 Flash: My daily driver
I've been using Gemini 2.0 Flash as my main model with Ask Rally for months, because it’s the best combination of traits—it’s incredibly cheap at $0.008 per 100 responses, and the responses feel eerily human. I was so married to it, in fact, that I suspected I was doing myself a disservice by not using a more powerful or up-to-date model.
The experiment revealed Gemini Flash 2.0 really was something special. Not only did it achieve the highest quality score at 84 percent, it outperformed its newer sibling with 52.2 percent accuracy. Gemini 2.5 Flash, despite costing six times more, dropped to just 44 percent accuracy and 21 percent quality. Model training is still more of an art than a science, and making the model better at one thing can make it worse at another. Sometimes an upgrade is a downgrade in disguise.
Kimi K2: The new model on the block
The biggest shock was Kimi K2, the large open-source model from Moonshot AI. At 56.9 percent accuracy, it edges out Claude 4 Sonnet—but costs 85 percent less. It delivers most of the leader GPT-4.1's performance at less than a third of the price. If you're running large-scale persona research, this changes the economics significantly, letting you be more ambitious with your testing. We would still prefer to use Gemini, given Google’s willingness to heavily subsidize prices, but if you run into issues with overactive safety filters or just don’t want to send your data to Google, self-hosting Kimi K2 is a viable option.
Our picks
Based on our testing, here's your decision guide:
Best overall value: Kimi K2
- 52.3 percent accuracy at $0.029/100 responses
- Nearly matches top performers
- Unknown but powerful
Best natural responses: Gemini 2.0 Flash
- 84 percent quality score at $0.008/100
- Sounds genuinely human
- Validate accuracy on your own data—answers may sound more believable than they are
Best accuracy: GPT-4.1
- 54.5 percent accuracy with good quality
- Higher cost justified for critical research
- Surprised me with consistent performance
Spending smart
After 60 experiments, the message is clear: Don’t assume expensive means better. Kimi K2 delivers premium performance at budget prices. Gemini 2.0 Flash creates the most human-like responses for less than a penny. Even GPT-4.1, despite my initial skepticism, proves its worth with consistent accuracy.
For AI-powered market research, these results change the economics entirely. You can achieve 70-80 percent accuracy at a fraction of traditional research costs. The tools exist today—you just need to know which ones to use.
Note on methodology: The five real-world studies we used were as follows (percentages are an average of the 12 models’ performance):
- Brick viaducts study (infrastructure preferences) —71.6 percent
- U.S. election study (political affiliation)—57.0 percent
- Gaming preferences study (game concepts)—50.8 percent
- Predictive personas study (B2B lead generation)—46.7 percent
- College planning study (education marketing response)—14.8 percent
The college planning study was a failure and deserves special attention. Every single model failed catastrophically at predicting how students and parents respond to education marketing. This wasn't a subtle failure—it was complete incomprehension of how families make emotional, high-stakes decisions about their future.
The pattern is clear: Models excel at logical, binary choices but fail at emotional, complex decision-making. The more human nuance involved, the worse they perform. In the case of the college planning study, we were testing 15 different messages head-to-head and trying to predict how well they would do on Facebook and Instagram ads, so there’s also a lot of room for noise here. This is our hardest evaluation (based on a customer we lost!).
Michael Taylor is the CEO of Rally, a virtual audience simulator, and the coauthor of Prompt Engineering for Generative AI.
To read more essays like this, subscribe to Every, and follow us on X at @every and on LinkedIn.
We also build AI tools for readers like you. Write brilliantly with Spiral. Organize files automatically with Sparkle. Deliver yourself from email with Cora.
We also do AI training, adoption, and innovation for companies. Work with us to bring AI into your organization.
Get paid for sharing Every with your friends. Join our referral program.
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools




 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software

 Mike Taylor
Mike Taylor
.png)
.png)
Comments
Don't have an account? Sign up!
Great study! I'm really curious about the prompting methodology you used across the different models. Did you optimise the prompts for each model individually? I wonder if some of these quality differences might be down to which models respond better to your particular prompting style rather than them being inherently more human-like. I'm struggling myself to get decent, simple human-sounding answers!