
Hello, and happy Sunday! Our course How to Write With AI taught by Evan Armstrong is open for early bird registration. You’ll learn how to fashion expert prose and get your writing to resonate with your intended audience while harnessing the latest AI technology. If you enroll before Jan. 23, you can jump the nearly 10-000-person strong waitlist for our new AI email tool, Cora. Don’t miss out—our next cohort kicks off on February 13.—Kate Lee
Was this newsletter forwarded to you? Sign up to get it in your inbox.
Release notes
Google launches Titan: Languages models that can learn from experience
In 2017, Google laid the groundwork for the AI boom, writing the seminal paper introducing the transformer architecture that has powered the language models that have come since. This week, the company claimed it’s taken another step forward with its new Titans architecture. It solves one of the outstanding problems with the previous generation of artificial intelligence models: They learn from experience, instead of forgetting what you tell them.
With better memory, AI models could recall past conversations, learn from new data, and—hopefully—never make the same mistake twice. If researchers have indeed cracked the code for AI memory, then we may soon enter an age of AI where users can trust and rely upon chatbots in a much deeper way.
The limitations of transformers—and what the new research means
AI chatbots are like geniuses with memory loss. You need to provide context for each and every conversation because, while they’re smart and perceptive, all they know is what was in their training data and the information you share.
Short-term memory is not a bug of modern AI, but rather a feature of the transformer architecture. In the same way that using a specific language can change how you think, these new AI architectures could shape the nature of the interactions we have with language models.
In 2017, Google researchers published “Attention Is All You Need,” which defined transformers and ultimately led to the development of OpenAI’s ChatGPT (GPT stands for “generative pre-trained transformer”). This week it shared Titans, a new architecture that could be the next step forward and enable AI to continuously learn. Meanwhile Sakana AI, a Japanese R&D firm that makes use of ideas from nature, published the paper "Transformer²." Each takes inspiration from how human brains work. They build on the short-term attention of transformers and aspire to impart the ability to act as a long-term, more persistent memory. Would you trust AI more if LLMs remembered past conversations, learned from them, and always cited sources?
Here is how transformers work today and some of the new ideas proposed by the Google and Sakana teams:
The (non)persistence of memory: Transformers’ key strength is being able to singularly focus on a provided prompt and predict how it might continue one word at a time. They train their “brains” for months on giant datasets before being deployed to predict one word at a time in order to answer a given prompt. But by the time they’re deployed, they’re also unplugged, so to speak. They are incapable of learning anything new after that point. While transformers get more powerful with scale, they're fundamentally constrained by their original design: They can't learn from conversations, build long-term memory, or adapt to new situations without extensive retraining. In practice, if a prompt gets too long, performance dramatically declines.
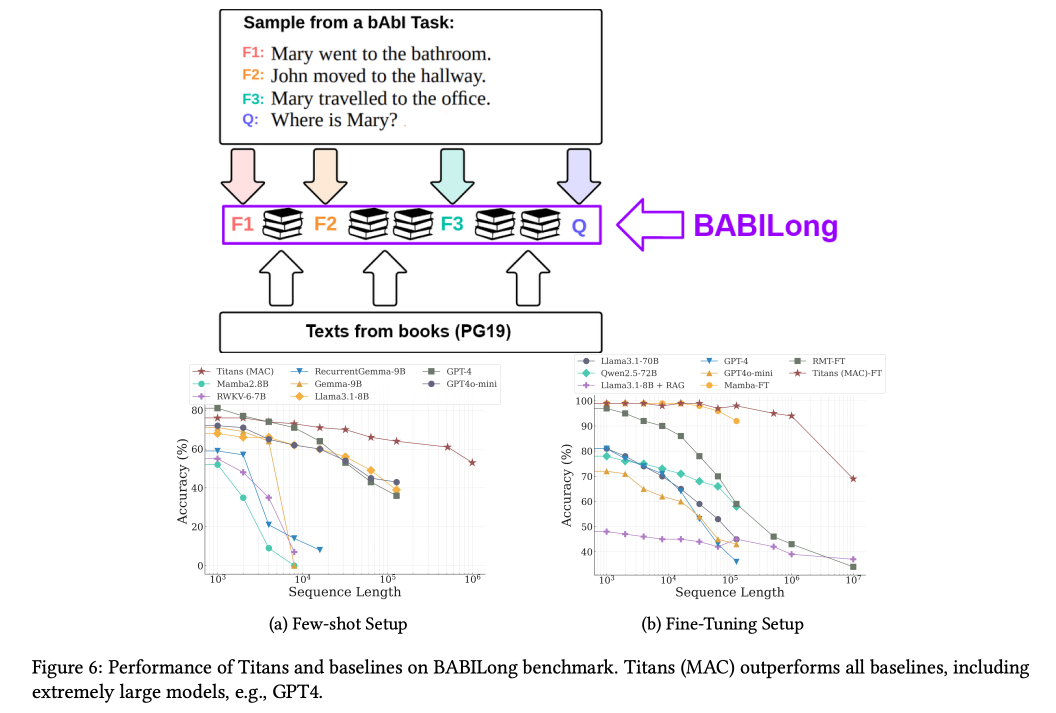
Titans’s “surprise” memorization mechanism: Google’s Titans hopes to improve on the limitations of transformers by learning how to memorize key bits of information in a long prompt. It tries to mirror how human memory works, complete with a “surprise” mechanism that helps it decide what information is worth remembering. Just as our brain prioritizes events that violate our expectations—i.e., being surprising—Titans attempts to simulate the same process by checking if the words it is processing are themselves surprising or associated with a past surprise. Like our brains, the new architecture can handle much more information than the current models, handling sequences of over 2 million tokens long (about as long as the entire Harry Potter series, twice over). The promise of Titans is that a next-generation language model could hold all of that information in its memory at once—and learn from it. Titans outperforms OpenAI’s GPT-4 on many benchmarks, including Babilong, which is focused on testing if models can remember what happened in a story.
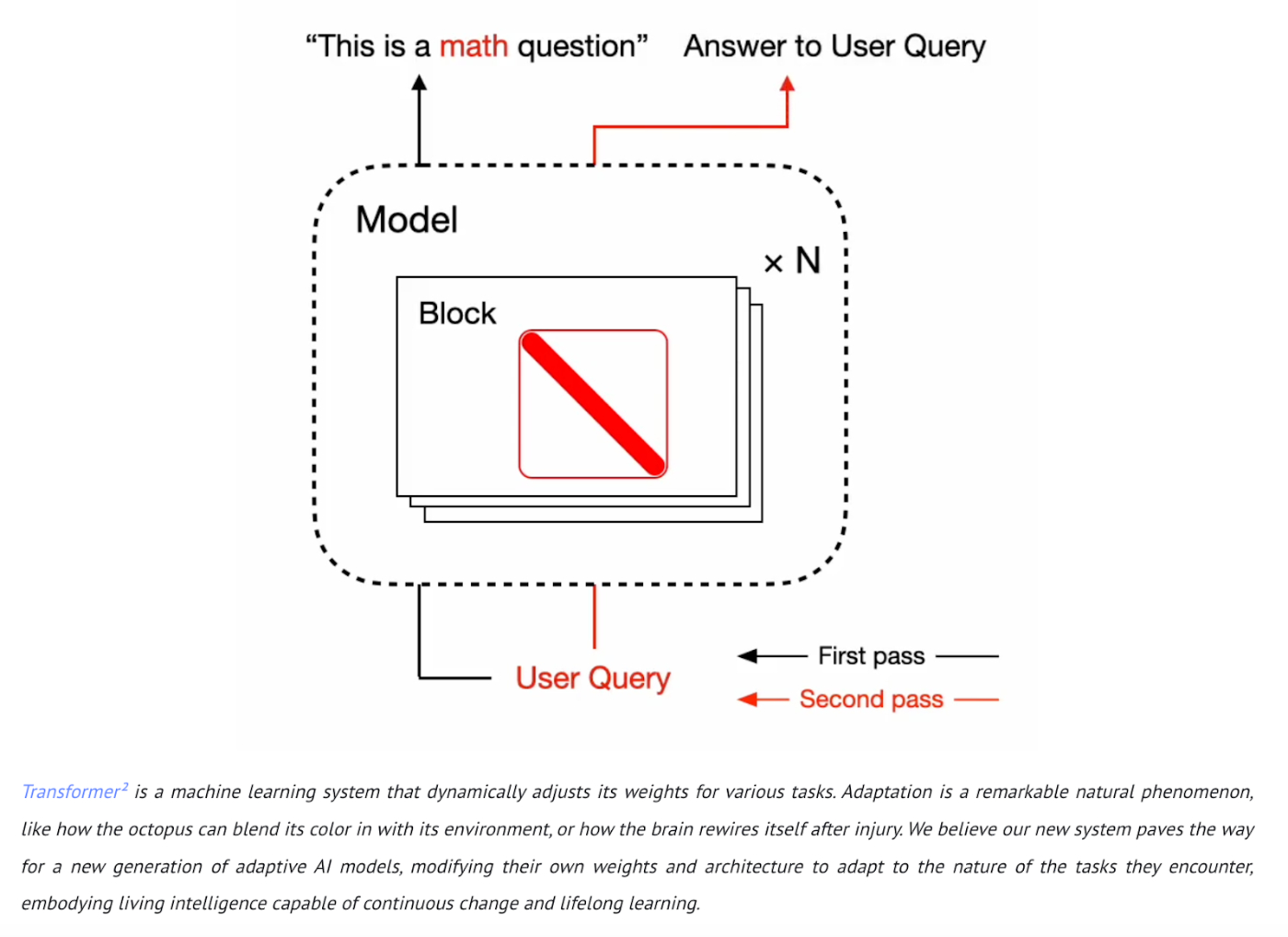
Transformers²’s self-adaptive AI: For Transformers², the Sakana AI team took inspiration from how the human brain rewires itself after an injury. This vision of self-adaptive AI is at the heart of its two-step approach for Transformers². First, the model analyzes the incoming task to understand its requirements before attempting to learn; then it dynamically adjusts and provides results tailored to that task. Just like octopuses use camouflage, changing their skin patterns to match their environment, Transformers² adapts its entire architecture on the fly. Both Google and Sakana have effectively made AI models more adaptive, potentially a step change from the status quo.
There have been many purported “transformer killers,” but better benchmark performance is only half of the battle. Transformer-based models are so capable because many people have found them to work in practice and have built tools around them. It remains to be seen if either of these architectures will similarly entice a community of builders. Conditions may be ripe for the industry to adopt a new approach. Yann LeCun, Meta's chief AI scientist, has argued that current transformer-based models are fundamentally limited because they lack reasoning and true understanding of the world. François Chollet, a prominent AI researcher, said that architectural innovations could matter more than making a bigger transformer with raw computational power. Even Ilya Sutskever, formerly OpenAI's chief scientist, has acknowledged that current architectures may be approaching their limits (though, he says, they're still more than capable enough to get us to AGI).
Why AI architecture design matters
Hundreds of millions of people are using ChatGPT, Claude, and other AI apps, but we’re still learning how exactly people are using them. A World Bank study released this week showed remarkable learning gains for students using AI tutoring, while a Swiss study published earlier this month warned about AI's potential to reduce critical thinking skills among users. Much like calculators quietly transformed how we engage with mathematics, AI has the potential to reshape how we approach skills as fundamental as learning, critical thinking, and creativity.
With any new transformative technology, thoughtful design is paramount. If computers were designed to be used standing up with a keyboard in one hand and a mouse in the other, would that have changed how we use them? Would people behave differently today if we had become obsessed with Siri when it launched in 2011, and we controlled our smartphones exclusively through voice commands?
As we design the next generation of AI systems, we have a chance to build them not just to mirror our intelligence, but to enhance them in ways that preserve and amplify what makes human thinking unique: our creativity, our ability to learn and adapt, and our capacity for deep understanding. At their best, AI systems could beautifully complement our humanity by changing and adapting as we do.—Alex Duffy
Now, next, nixed
The current state of prompt engineering techniques: moving from step-by-step reasoning to parallel exploration and then multi-agent simulation.

Knowledge base
"I Asked 100 AI Agents to Judge an Advertisement" by Michael Taylor/Also True for Humans: Want to pressure-test ideas without spending a fortune on focus groups? Turns out, you can—with AI agents. Prompt engineer Michael Taylor takes us through “personas of thought,” a technique he uses to simulate virtual focus groups with diverse customer perspectives. Read this for a how-to guide on prompting AI to roleplay in your user research. 🗨 If you have a burning question that you'd like to put to 100 AI agents, submit it via this form, and Michael may answer it in his forthcoming advice column.
"God Is in the Bubbles" by Evan Armstrong/Napkin Math: When Trump's second term begins tomorrow, Silicon Valley's finest will flood Washington. Their scripture will be a new book by Byrne Hobart and Tobias Huber called Boom that argues bubbles aren't just good—they're practically divine. Marc Andreessen and Peter Thiel love it. But when “progress” becomes a spiritual mandate rather than a measurable outcome, who's really benefiting? Read Evan’s review for a critical look at the ideology driving tech's political ambitions and why treating bubbles as gospel might not be great for the rest of us.
"A Time Machine for Your Email" by Brandon Gell/Source Code: We’re reinventing email—and bringing zen to your inbox. Cora started as a solution to automating email replies, but it turns out, deciding which emails to reply to is an even more time-consuming task. Using AI, Cora sorts urgent emails from non-urgent, drafts responses, and delivers a twice-daily brief of everything else you need to know. Read this if you’re looking for an email methodology that leaves inbox zero in the dust. 🔏 Join the waitlist to try it yourself—Every paid subscribers get priority access.
🎧 "An Inside Look at Building an Email Client in Three Months" by Rhea Purohit/AI & I: It took Every entrepreneur in residence Kieran Klaassen one evening to build the first MVP of Cora. One month post-launch, the latest product from Every Studio has a nearly 10,000-person waitlist. In the latest episode of AI & I, Dan Shipper sits down with Kieran and Brandon Gell, head of Studio, to chat about building apps that stick. In a world where AI makes building fast and cheap, what matters is creating software that makes users feel something. Watch or listen to this if you care about building products with a strong POV. 🎧🖥 Watch on X or YouTube, or listen on Spotify or Apple Podcasts.
“Why There’s No ‘Right’ Way to Use AI” by Rhea Purohit/Learning Curve: We've all been there—feeling like everyone else has cracked the code on using AI while we're still fumbling in the dark. Rhea's breakthrough came from an unexpected place: doing mundane Excel calculations for paperwork. Unlike conventional software, where there’s a “right” way to do things, AI is fundamentally probabilistic, and generative AI tools are subjective. Read this for a perspective shift that might just cure your AI imposter syndrome.—Aleena Vigoda
From Every Studio
What we shipped this week
Better emails, all around: Cora is our re-imagined email experience, simplifying time spent in your inbox. It takes the clutter in your inbox, separates out your important messages, and synthesizes the rest into twice-daily summaries (or “briefs”). One month in, we’ve learned that people either love Cora or don’t use it—and some people (like Anthropic chief product officer Mike Krieger) even miss it (when it’s down).
This week, we improved the way we categorize messages to make sure time-sensitive emails don’t get lost in your briefs. Cora general manager Kieran Klaassen also shipped:
- More accurate content summaries
- The option to disable draft replies
- A cleaner expanded view on email threads
What’s in progress: revamping how we parse emails into briefs and categories from the ground up. Follow the changelog, leave feedback, or request a product feature.
Train Spiral on your favorite outputs: Save great content to your example set to set a great example for your Spiral. (Come again?) You can improve the output of your frequent Spirals by providing it with the outputs you want to produce more of. For even better results, combine this feature with Spiral's in-app editing tools to fine-tune your content exactly how you want it.
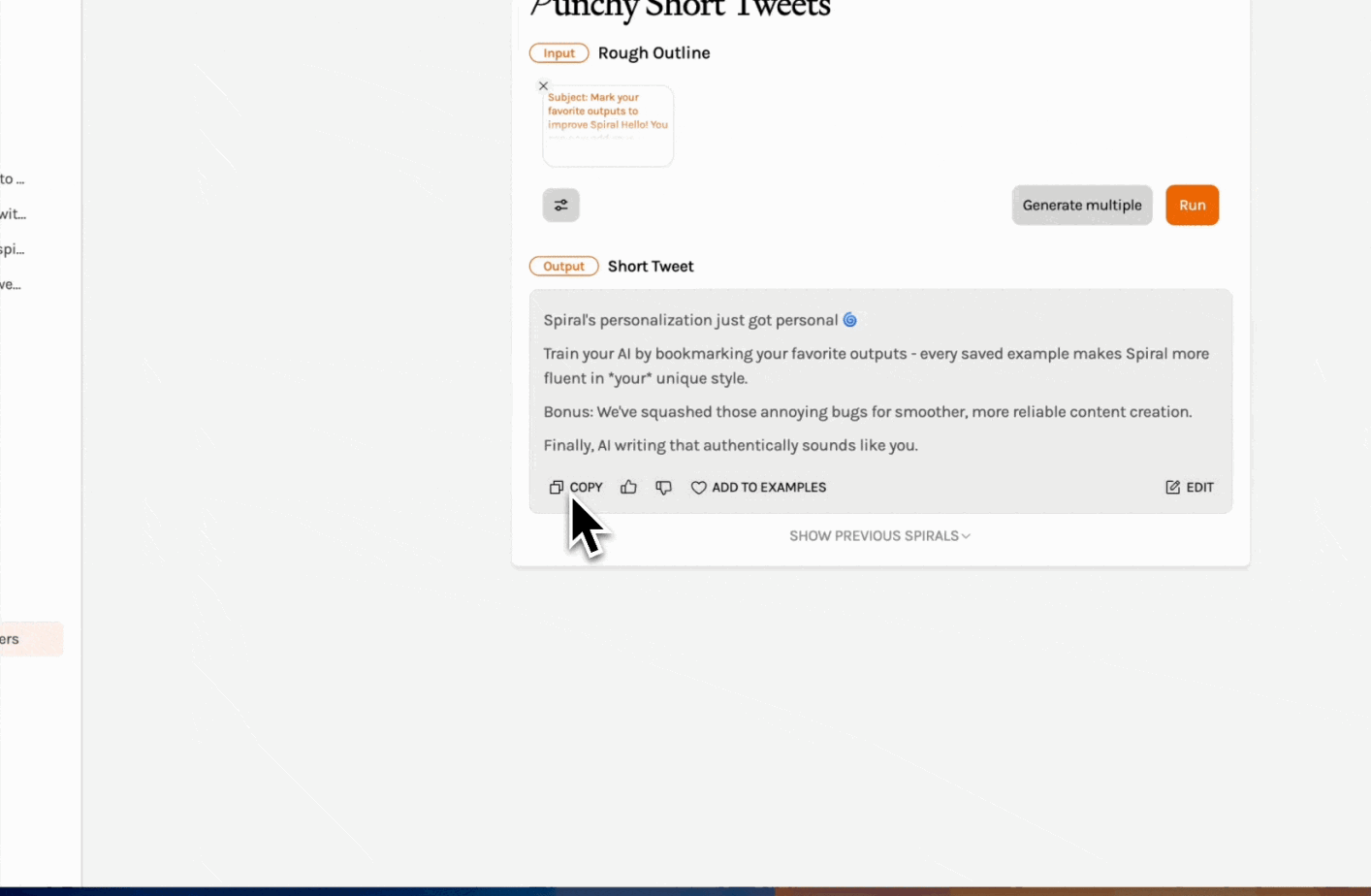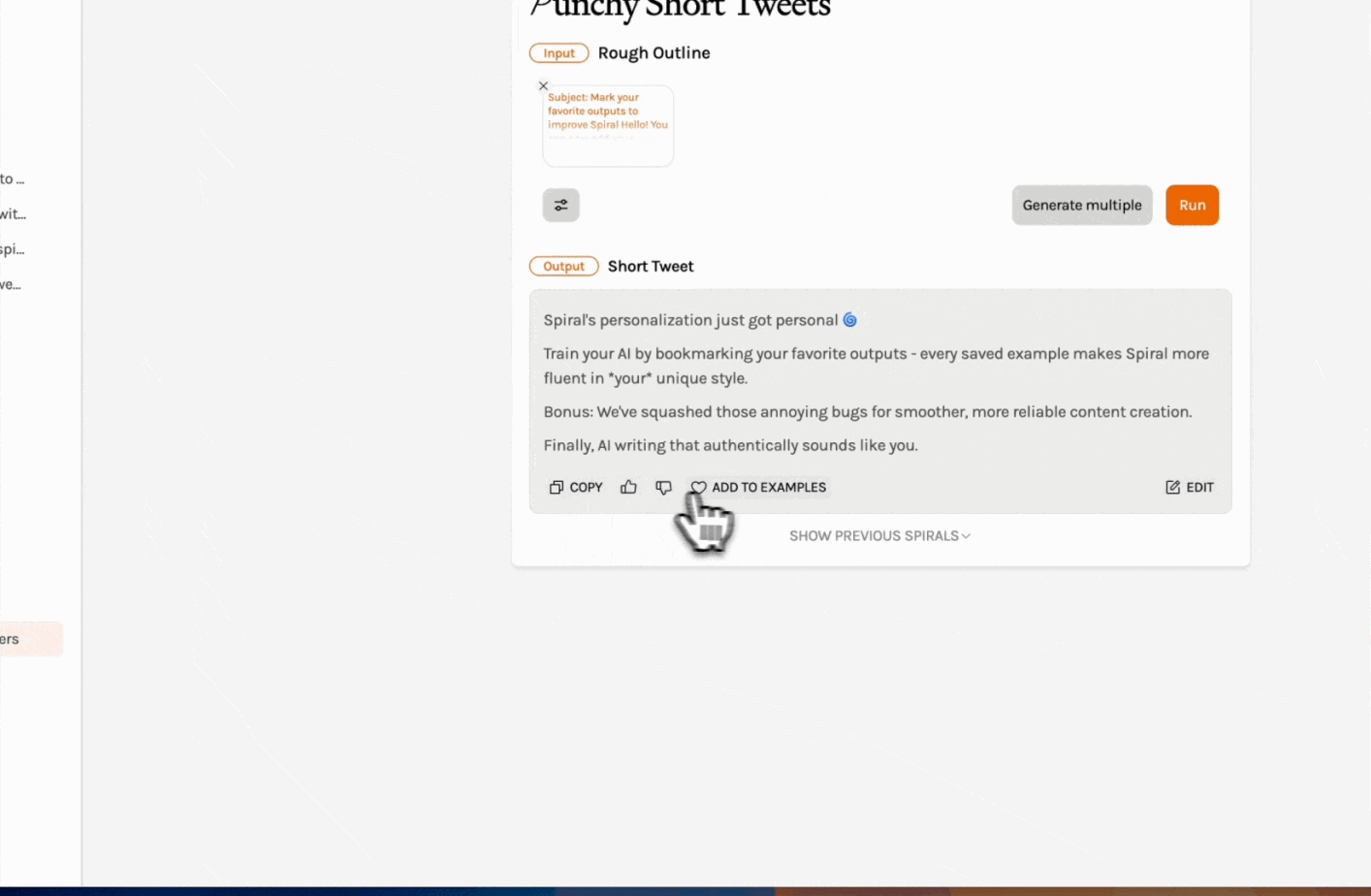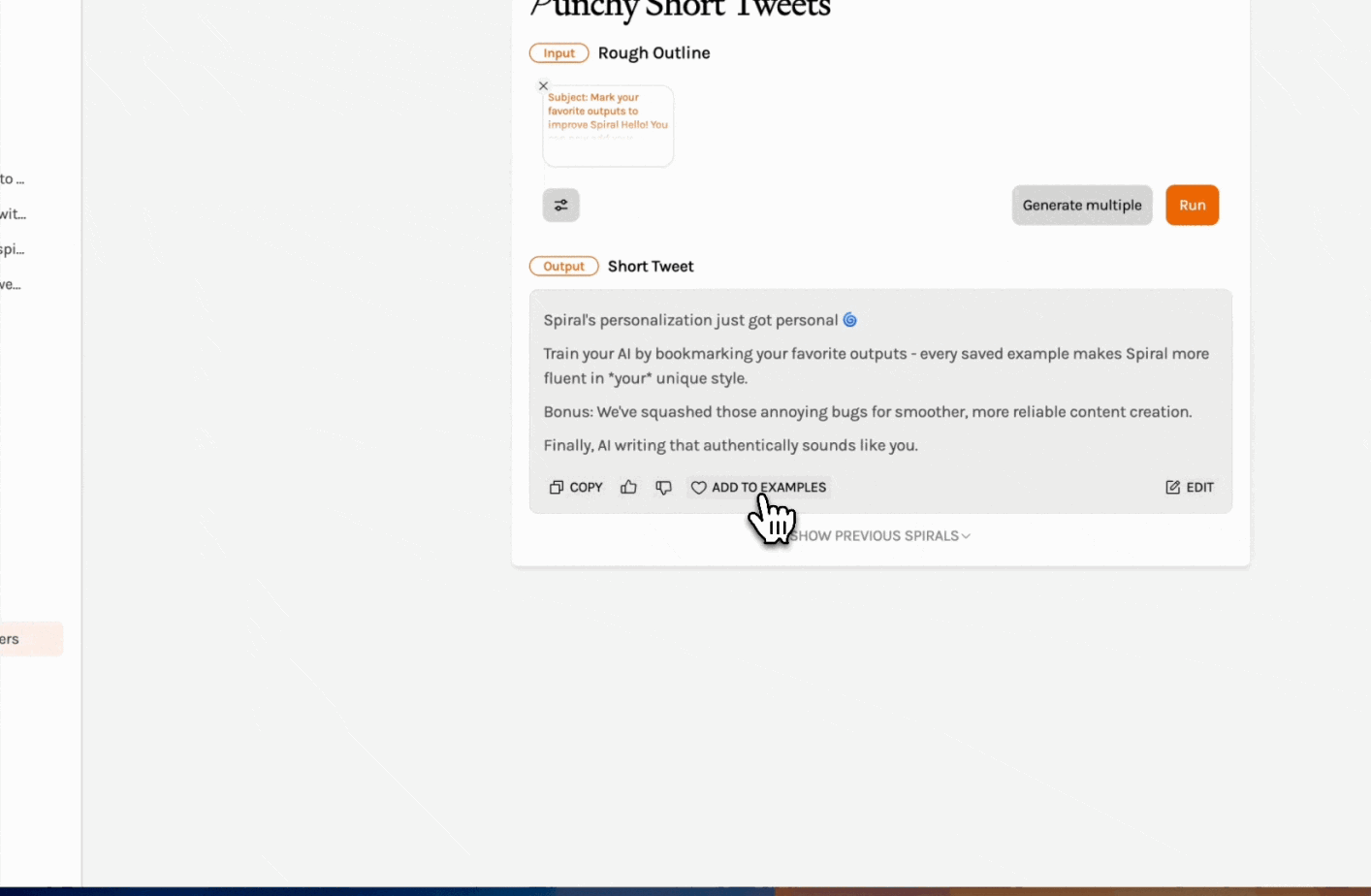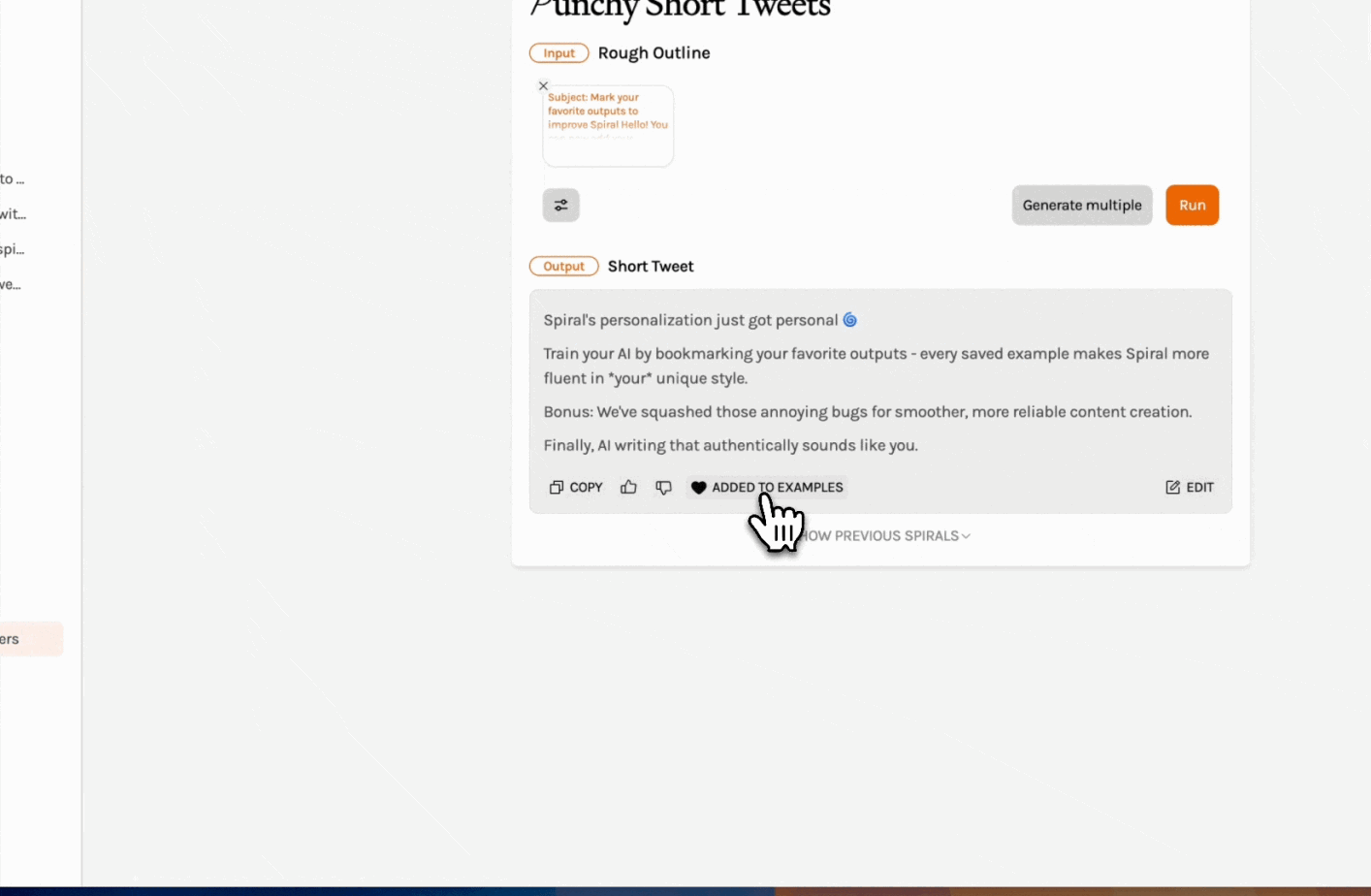
Paywalled trial experiments with Sparkle: When you sign up for Sparkle, our AI file organizer for your Mac, you get a 15-day free trial. While we’re keeping this period free of charge, we’re testing different onboarding strategies to see what works. How might a hard paywall—where users have to input an (uncharged) card number to begin their trial—impact the conversion rate to paid users? And what consumer behaviors might we see with Sparkle that are also true of Spiral and Cora?—AV
Alignment
AI gets spiritual. While visiting an ashram in south India, I’ve been trying to turn on, tune in, drop out, as Ram Dass would say. Unfortunately, I couldn't drop AI. During a 14-km walk near Chennai, I saw massive billboards advertising a guru's spiritual AI chatbot. Scan the QR code for instant enlightenment from his distilled books and teachings. My reaction cycled from disgust to surprise to reluctant recognition. The logical part of me understands—training an AI on decades of spiritual teachings is the perfect scaling of wisdom. But the human part of me is scared, not that AI will give wrong answers, but that it'll give better ones than humans. If you can turn to a chatbot to explain the mysteries of existence, what's left for us? I don't know. But as I continued my pilgrimage, I wondered if seeking wisdom was never about finding the right answers, but about being human enough to ask the right questions.—Ashwin Sharma
Hallucination
What if our keyboards were made out of terracotta?

That’s all for this week! Be sure to follow Every on X at @every and on LinkedIn.
We also build AI tools for readers like you. Automate repeat writing with Spiral. Organize files automatically with Sparkle. Write something great with Lex.
Get paid for sharing Every with your friends. Join our referral program.
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools




 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software
.png)

.25.09_PM.png)
 Alex Duffy
Alex Duffy
Comments
Don't have an account? Sign up!