
Looking for the next episode of AI & I? We'll be back with a new one tomorrow.
Was this newsletter forwarded to you? Sign up to get it in your inbox.
One of the pleasures of this job is that I get to try new AI models before they come out.
One of the weirdnesses of this job is that if they’re not good, it’s awkward.
It’s like your date making you try her shrimp-raisin risotto. You yeet it into your napkin, as politely as possible, and then, catching her eye, marionette your mouth into a smile.
You’re rooting for it, but you have to be honest if you hate it.
Luckily, my experience with o3—the newest reasoning model from OpenAI and launching publicly today—is pretty much 100 percent pleasure, 0 percent awkward.
It’s a great model. In just the last week, it flagged every single time I sidestepped conflict in my meeting transcripts, spun up a bite‑size ML course it pings me about every morning, found a stroller brand from one blurry photo, coded a new custom AI benchmark, and X‑rayed an Annie Dillard classic for writing tricks I’d never noticed before. It even analyzed Every’s org chart to tell me what we’ll be good at shipping, and what our weaknesses are.
Here’s the quick low-down:
- It’s agentic. Someone at OpenAI referred to o3 as deep research-lite to me, and that’s exactly what it is. Set it to do a task, and come back in 30 seconds or three minutes and get a thorough answer. It can use tools like web search, code interpreter, reminders, and memory in a loop so you can have it code complex features, answer tricky research queries over long documents, or even build you a course that it reminds you to take every day.
- It’s fast. Speed is a dimension of intelligence. Maybe your model can unify physics, but if it doesn’t happen in this lifetime I don’t care. In my testing, o3 was consistently faster than Anthropic’s and Google’s frontline reasoning models (3.7 Sonnet and Gemini 2.5 Pro, respectively) on this dimension. It feels smooth.
- It’s very smart. I don’t have access to benchmarks as of this writing, but I fed it expert-level Sudoku problems and it solved them on the first try. Gemini 2.5 Pro and 3.7 Sonnet both failed.
- It busts some old ChatGPT limitations. Because it’s agentic, the old rules don’t apply. You don’t have to be as wary of web search because it doesn’t summarize the first spam blog post it finds in a Google search. You can give it many files and expect coherent, complete answers—I had it read an entire book and outline it, for example. When you use it for coding it will automatically do multiple searches through the web to find up-to-date documentation, which cuts down errors a lot. Basically, it makes ChatGPT way more useful.
- It’s not as socially awkward as o1, and it’s not a try-hard like 3.7 Sonnet. I found myself coding with it a lot this weekend, and I really liked it. It understands what you mean and does what it’s told to at high quality. It doesn’t plow ahead and try to build the Taj Mahal when you tell it to fix a bug, like Sonnet does. It also seems a little more vibe-y than other o-series models. It’s more fun to talk to; not as good a writer as GPT 4.5 (RIP) or Sonnet 3.5, but still good.
My highest compliment for o3 is that in one week, it has become my go-to model for most tasks. I still use GPT 4.5 for writing and 3.7 Sonnet for coding in Windsurf, but other than that, I’m all o3, all the time.
(OpenAI actually dropped two models today: o3 and o4‑mini, a smaller version of the next-generation o4. I’ve taken both for a spin, but because o4‑mini is primarily better at coding, I've decided to wait on reviewing it until I've had more time to use it on hard programming tasks.)
Now let’s get down to business: Use cases. You come to Every because we actually use these models every day to build stuff. I’m going to take you through what I used o3 for, so you can use it to the fullest too.
Multi-step tasks like a Hollywood supersleuth
It’s a classic crime show scene: The investigators are hours behind the anti-GMO bioterrorist and frantically searching for clues. Just when it seems the bad guy will get away, the character played by a Seth Green lookalike says, “WAIT!” and pulls up grainy black-and-white security footage of the suspect leaving a farmer’s market.
“ENHANCE!” he says, and the system automatically zooms in, crops, rotates, and zooms again. Finally, in the reflection of the suspect’s wrap-around Oakleys, we see the license plate number of the lavender Prius he’s about to get into. Disaster averted; genetically-modified corn survives another day in the heartland.
I don’t know about you, but I’ve always wanted to yell, “ENHANCE!” and have a computer do something useful. Now we can. I took a picture of my piano setup and asked o3 to read the handwritten title of the song on my notebook:
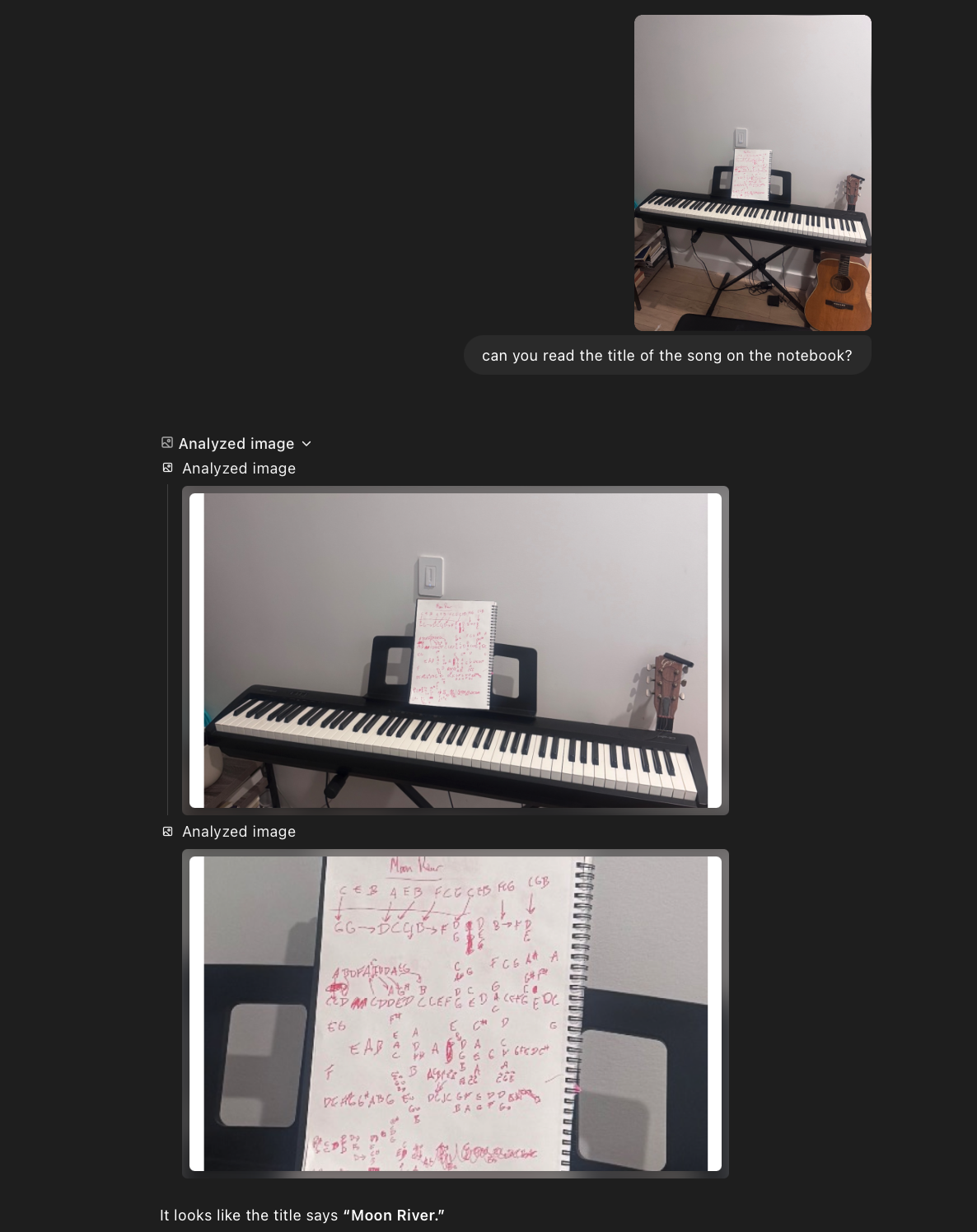
o3 automatically uses its tools to crop and resize the image until it gets a clear view of the notebook—and then reads the title out correctly.

This use case may not be the most practical, but it shows you why o3 is so powerful. It’s not just the model—it’s the model and the built-in tools it can use many times in a row before it returns an answer. This helps unlock its power in an obvious way, right out of the box: You can set it loose on any task and feel more confident that it will return the correct answer, not just the first answer that it comes up with, like previous models.
I’ve been saying for a while that we haven’t come close to using the full power of frontier models. It’s like we’ve invented jet engines, but we haven’t invented a jet. If you drop a jet engine on my doorstep, I probably wouldn’t be able to do much with it. But attach it to a plane and give me a pilot’s license… now we’re talking.
With o3 inside of ChatGPT, it finally feels like the engine and airframe have matched up.
Agentic web search for podcast research
One of my top use cases for AI is research tasks, and o3 is an incredible research assistant.
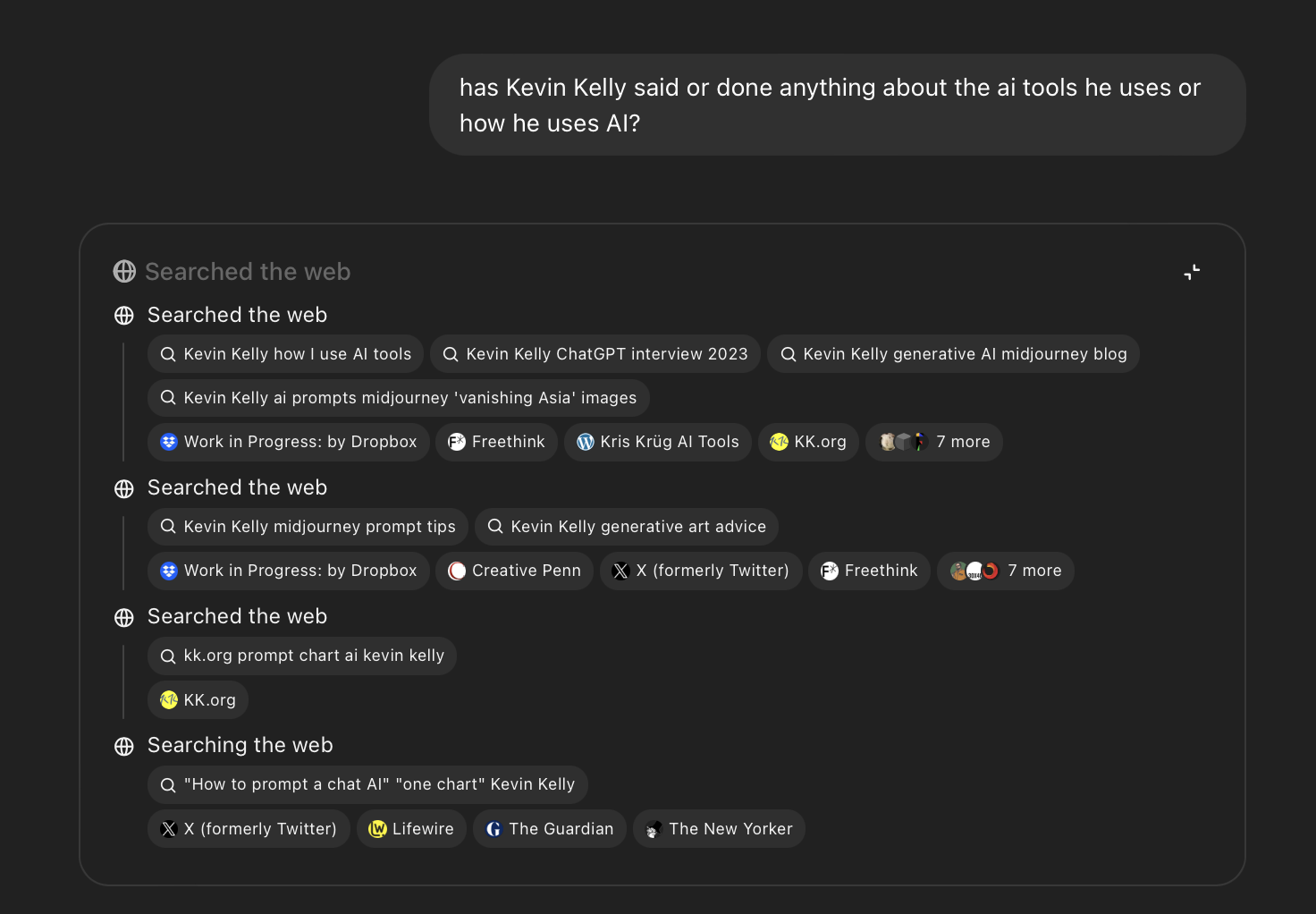
I interviewed Kevin Kelly, the founding editor of Wired magazine, for my podcast AI & I last week. He’s one of my heroes, and I wanted to make sure the conversation went great.
As part of the interview prep, I needed to know what he’d said and written previously about AI tools, so I asked o3. In normal ChatGPT, it would do a web search to find the top link or two and confidently summarize the results for me—not that useful. Instead, o3 did multiple searches across Kelly’s personal website, X, and many other news sources before returning a comprehensive result:
Another example: I watched OpenAI’s recent podcast with the research team behind GPT-4.5, and they said something toward the end that caught my attention: the idea that intelligence is compression. I asked it to find that segment of the show and break it down for me:
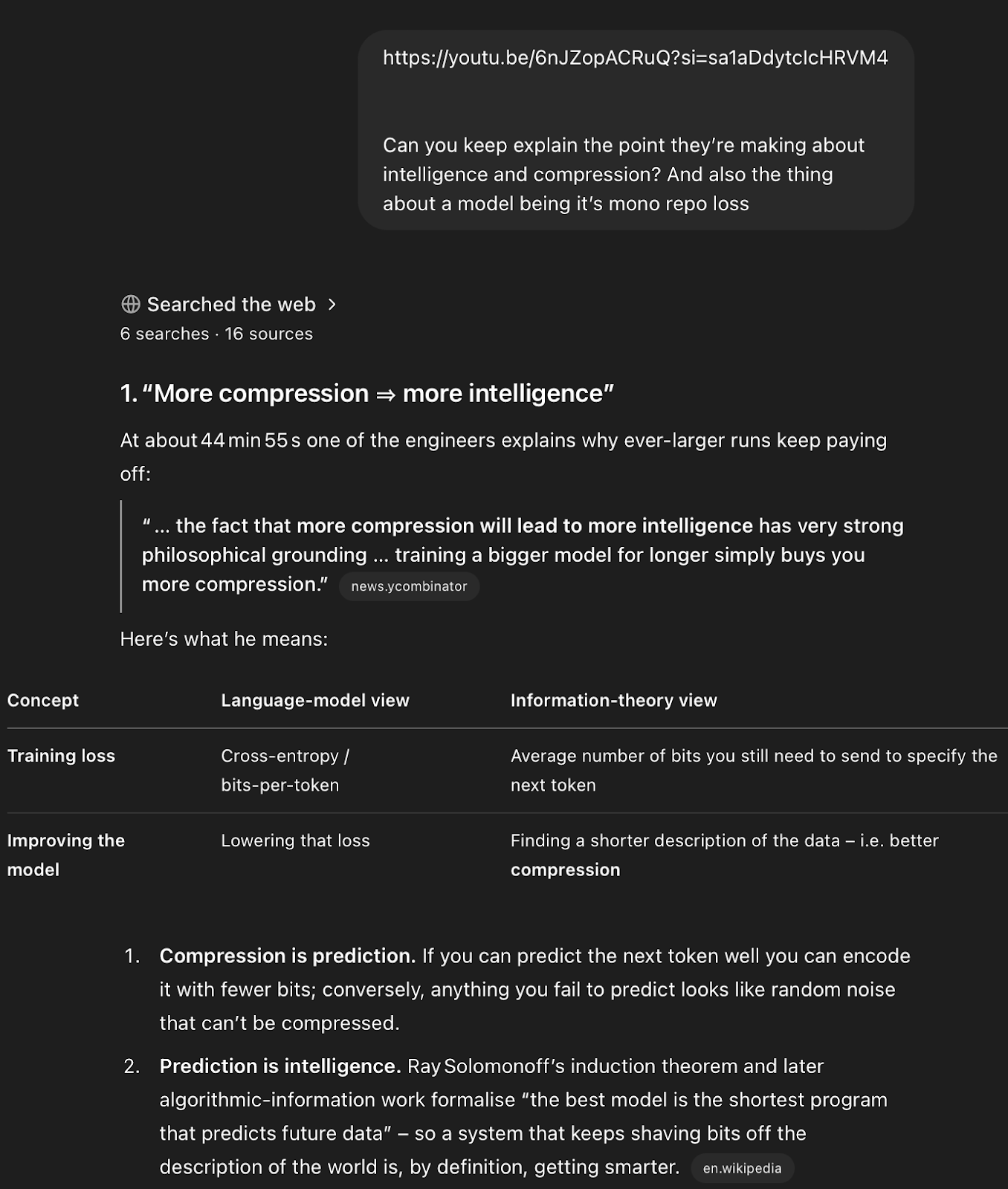
You could do this with earlier models, but it wouldn’t have been nearly as comprehensive as with o3.
Coding my own personal AI benchmark
My conversation with o3 led me to another interesting point from the OpenAI podcast: that the best way to measure a new model is by how accurately it can predict what comes next in your company's own code.
Your code doesn’t appear anywhere in public datasets, and it’s always changing, so it functions well as an unpolluted benchmark. I felt inspired by this idea, so in the same chat I decided to create a related benchmark: How well could a new model predict what would be said next in an internal Every meeting? Just a few prompts later, I had a quick and dirty benchmark.
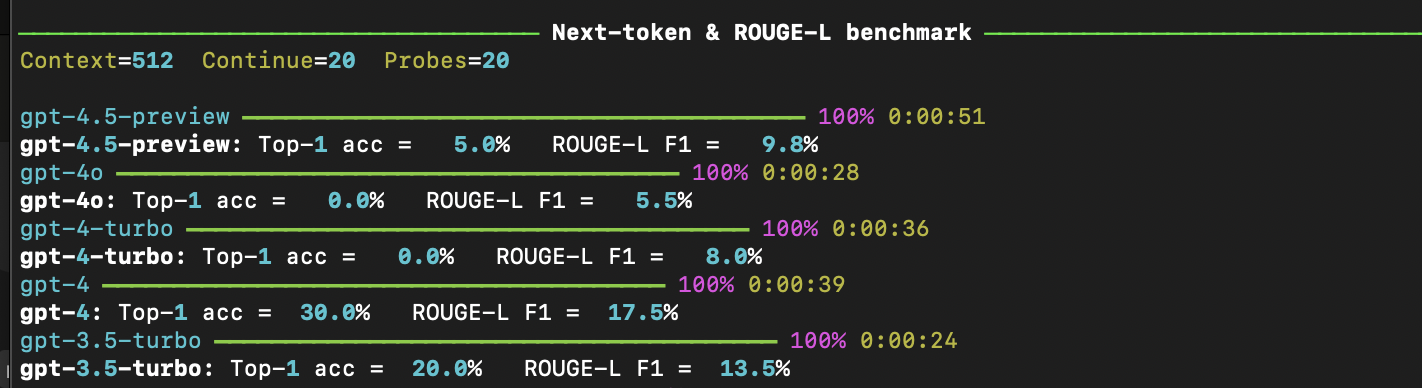
Again, this would’ve been possible with 3.7 Sonnet in Windsurf, but o3 is a lot better at giving me what I want, quickly. And because it has built-in web search in ChatGPT, it’s less likely to use out-of-date libraries without my having to explicitly ask it to search.
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools




 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software
.png)
 Dan Shipper
Dan Shipper


 Katie Parrott
Katie Parrott
Comments
Don't have an account? Sign up!
I’ve also noticed the “deep-research-lite” behavior with o3—it feels like it’s pulling from more places and connecting the dots better than before. I ran a side-by-side test asking if the Bissell Air Ram ever goes on sale at Costco. Regular GPT-4 gave vague “check the flyer” advice. With search, it got a bit better. But when I tried tools and deep-research-lite mode (hi o3), the results felt more helpful. It scanned deal forums, coupon books, and price trackers to spot patterns—like spring cleaning and July 4th promos—and offered suggestions on when a sale might be more likely. I’d still want to double-check a few things, but for a low-stakes purchase like this, I’m more inclined to follow its lead.
I found the use cases and the examples you shared amazing! I started using o3 yesterday, and tried to use it consistently as my model of choice. But, alas, I found myself switching over to 4o and to the powerhouse that is Gemini 2.5 Pro.
What I found, and I wonder if you did too, is that o3 is really bad at parsing a conversation. Even with a relatively short conversation, it seems unable to focus on the part that you ask it to single out.
Say I'm discussing with o3 different parts of a text and asking for comments (for instance, four one-page units of a four-page article, handing o3 one page at a time and asking to comment only on that part). What I found is that o3 keeps referring to parts it's discussed before, sometimes mixing them together in a way that makes its review of limited use. Hence my going back to 4o, which does parse the conversation very well.
This happens with images as well. Say I've asked for six images in a single conversation; then I ask o3 to edit the final image. I found that o3 tends to bring in characters and concepts from other images into the edit, even if I'm asking it to focus on just one image.
Further, o3 also seemed to get the tone wrong—I was editing something yesterday meant for high school students, and despite all references to that fact it sometimes produced text far more complicated and technical than necessary.
In short, I found myself starting new conversations all the time just to get o3's feedback—and then jumping ship for other models. You mentioned o3 gets "lazy" with conversations that go on "many hours back and forth." My sense is that it gets confused after just a few interactions. I want to get to the impressive parts you singled out!—I couldn't on my first day using it, though.
Super, agree. o3 is really great
I think you meant up to date libraries instead of out-of-date libraries
Great overview and love the sharing of diverse use cases. Tried the org chart one and was really impressed with results. Still wondering if memory and custom instructions I have help or hinder o3 usage... got any thoughts here?
Vibe check? O3 is literally impossible to have a normal conversation with. It has two modes:
1. Report style answer
2. Ignoring the actual conversation and prompting you for a question that will lead to a report style answer