
Was this newsletter forwarded to you? Sign up to get it in your inbox.
I’ve written about why having your AI coding assistant plan before it codes lets you ship faster than jumping straight to code. It’s my method for making my AI smarter with every feature.
For example, when I needed to implement Cora’s email bankruptcy feature—clearing 53,000-email inboxes without deleting anything important—I didn’t start by coding. I created a research agent to plan instead.
I thought this would be an easy feature. Bulk archive 53,000 emails—how hard could it be? I asked the research agent to analyze our own bulk operation patterns, check API limits for mass actions, and propose three implementation approaches with tradeoffs.
Twenty minutes later, it came back with a reality check: Gmail rate limits would kill us at 2,000 emails, our system would timeout on long operations, and the user would have to wait too long for the result. I thought it would be a quick feature, but it turned into a three-day architectural challenge. Planning had saved me from wasting time building the wrong thing entirely.
You can avoid building the wrong thing, too. I’ll show you the concrete tactics that turn a planning philosophy into working systems, starting with how to run parallel research operations that teach your AI how you think. Look out for Github links throughout the article—I’ve added them so you can copy and adapt the exact agents and commands I use, rather than building everything from scratch.
The eight planning strategies
When you’re planning with AI, you’re running parallel research operations—each one a specialized agent gathering different kinds of knowledge. Then you work together: The agents bring findings, you make decisions, and together you combine and distill everything into one coherent plan.
It’s much faster for five agents to research in parallel than for a human to plan step by step. Your contribution to the process is taste, judgment, and context about what matters for your product and users.
I use eight research strategies, depending on the fidelity level, which refers to the degree of difficulty. Fidelity One is quick fixes like one-line changes, obvious bugs, and copy updates. Fidelity Two covers features spanning multiple files with clear scope but non-obvious implementation. Fidelity Three covers major features where you don’t even know what you’re building yet.
Strategy 1: Reproduce and document
What it does: Attempts to reproduce bugs or issues before planning fixes
When to use it: Fidelity One and Two, especially bug fixes
The agent’s job: Create a step-by-step reproduction guide
Prompt: “Reproduce this bug, don’t fix it, just gather all the logs and info you need.”
Right after the launch of Cora’s email bankruptcy feature, 19 users were stuck. They’d clicked “archive everything,” but the job failed. Instead of guessing the reason for the problem, I told Claude Code: “Loop through the AppSignal logs and diagnose this.” (AppSignal logs are our error tracking system that records what goes wrong in production.)
Five minutes later, I had a reply: Rate limit errors were being swallowed in production. The job hit Gmail’s limit, failed silently, and never resumed. Users would click “archive everything,” see a loading spinner, and wait forever—because when one batch failed, the entire job stopped, but we never told the user. That reproduction showed we needed batch processing and job resumption, not just retries.
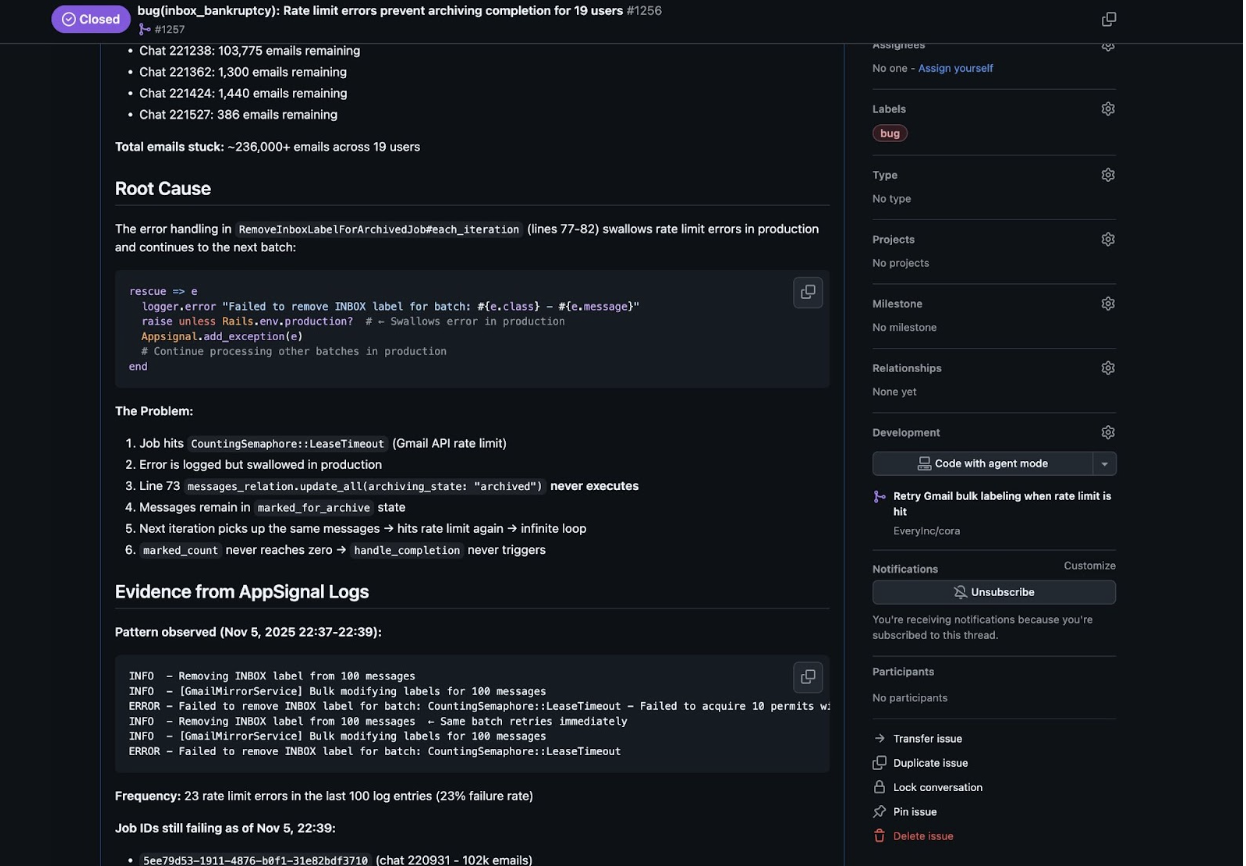
How to make this compound: To make sure that this issue wouldn’t happen in the future, I updated my @kieran-rails-reviewer agent—one of the specialized reviewers that automatically checks plans and code as part of my compounding engineering flow. I added to its checklist: “For any background job that calls external APIs—does it handle rate limits? Does it retry? Does it leave users in partial states?” We forgot to retry once. The system won’t let us forget again.
Strategy 2: Ground in best practices
What it does: Searches the web for how others solved similar problems
When to use it: All fidelities, especially unfamiliar patterns
The agent’s job: Find and summarize relevant blog posts, documentation, and solutions
Agent: “@agent-best-practices-researcher”
This strategy works for anything where someone else has already solved your problem—things like technical architecture, copywriting patterns, pricing research, or upgrade paths.
When I needed to upgrade a gem—a pre-built code library I use—that was two versions behind, I had an agent search: “upgrade path from version X to Y,” “breaking changes between versions,” “common migration issues.” It found the official upgrade guide, plus three blog posts from engineers who’d done the same upgrade and hit edge cases. That research took three minutes and prevented hours of trial-and-error debugging.
I’ve also used this for non-technical decisions: “SaaS pricing tiers best practices” returned frameworks for structuring pricing plans. “Email drip campaign conversion copy” found proven email templates. “Background job retry strategies” surfaced patterns in how other companies solved that problem at scale.
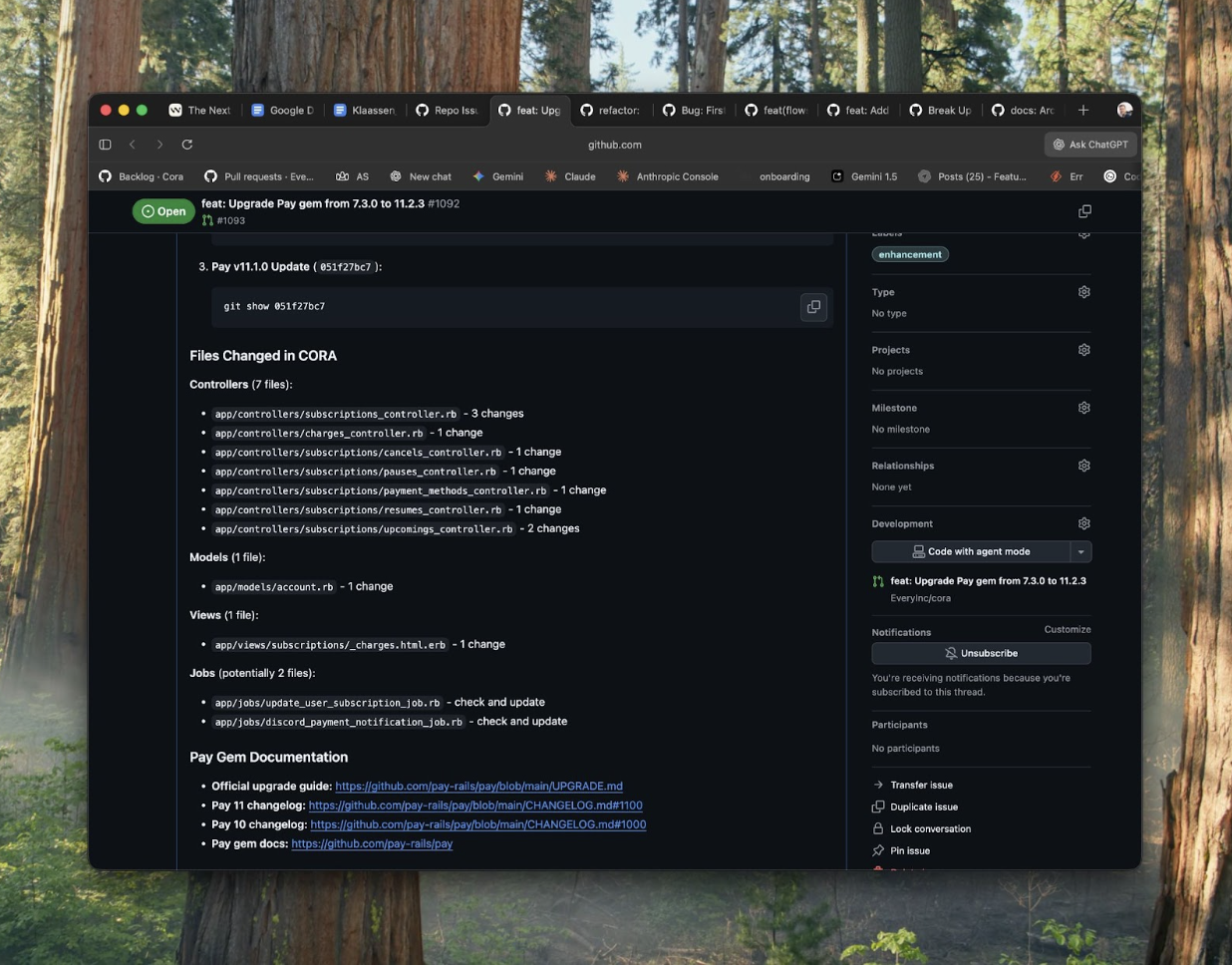
How to make this compound: When the agent finds a particularly useful pattern, I have it automatically save the key findings to `docs/*.md` files in my project. For instance, I’ve saved “docs/pay-gem-upgrades.md” for migration patterns and “docs/pricing-research.md” for pricing insights. Next time a similar question comes up, the agent checks these documents first before searching the web. My knowledge base is constantly growing and improving.
Strategy 3: Ground in your codebase
Become a paid subscriber to Every to unlock this piece and learn about:
- Stopping reinventing solutions your codebase already has
- Turning git history into institutional memory that prevents repeated mistakes
- And the 4 other programming planning strategies that teach your AI how you think
The Only Subscription
You Need to
Stay at the
Edge of AI
The essential toolkit for those shaping the future
"This might be the best value you
can get from an AI subscription."
- Jay S.
Join 100,000+ leaders, builders, and innovators

Email address
Already have an account? Sign in
What is included in a subscription?
Daily insights from AI pioneers + early access to powerful AI tools




 Front-row access to the future of AI
Front-row access to the future of AI
 Bundle of AI software
Bundle of AI software
.png)
 Kieran Klaassen
Kieran Klaassen

 Yash Poojary
Yash Poojary
.png)
 Katie Parrott
Katie Parrott